What are word embeddings?
 I do not own this image. Credit to 3blue1brown.
I do not own this image. Credit to 3blue1brown.Neural networks, which are machine learning architectures used to power many of the AI applications we use today, require data to be in a numerical format. However, words are not numerical. Word embeddings are a way to convert words into numerical vectors. These vectors can then be used as input to a neural network.
One-Hot Encoding
The simplest way to do this is One-Hot Encoding, whereby you create vectors with as many cells as there are words in your vocabulary. Each cell is set to 0, except for the cell corresponding to the word you are encoding, which is set to 1. This isn't great as it is a very sparse representation, uses a lot of memory and does not capture the relationships between words.
Word Embeddings
Word embeddings are an improved type of word representation that allows words with similar meaning to have similar representations (dense vectors). This is useful because it allows the neural network to learn the relationships between words. For example, in a word embedding space, the vectors for "king" and "queen" will be closer together than the vectors for "king" and "dog".
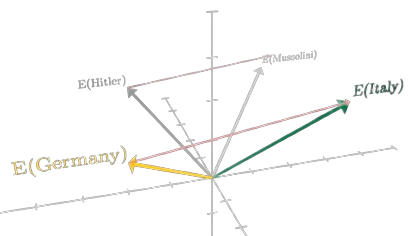
This allows us to perform some operations like addition and subtraction on the vectors or, conceptually, on the words they represent. We can find words that are semantically similar to other words, or do analogies, like A is to B as C is to ?. In vector space, this is effectively A - B + C = D. Exploring this surprising, and quite delightful, consequence is the point of this web app. By playing around with analogies we can see how the neural network has learned the relationships between words, and detect biases in the data it was trained on. (If you're interested in attempts at de-biasing pretrained word embeddings, start with this this paper).
Some popular pretrained word embedding models are Word2Vec (where it all began, Google), GloVe (by Stanford University, improved upon Word2Vec) and fastText (by Facebook, which can handle out-of-vocabulary words).
You can use the Gensim Python library to manipulate pretrained word embeddings. This article by IBM, YouTube video by AssemblyAI (which also shows how to use Gensim), paper summary by The University of Edinburgh and, for those with shorter attention spans, YouTube short by 3blue1brown are all great if you want to learn more.
LLMs
Even pretrained word embeddings are relatively old-fashioned nowadays. The problem with pretrained word embeddings is that they are static - they don't change based on context. This paradigm changed with the advent of pretrained language models like ELMo and Google's BERT. BERT is a transformer model that can be fine-tuned for a specific task. It is the basis for many of the language models we use today.